Introduction
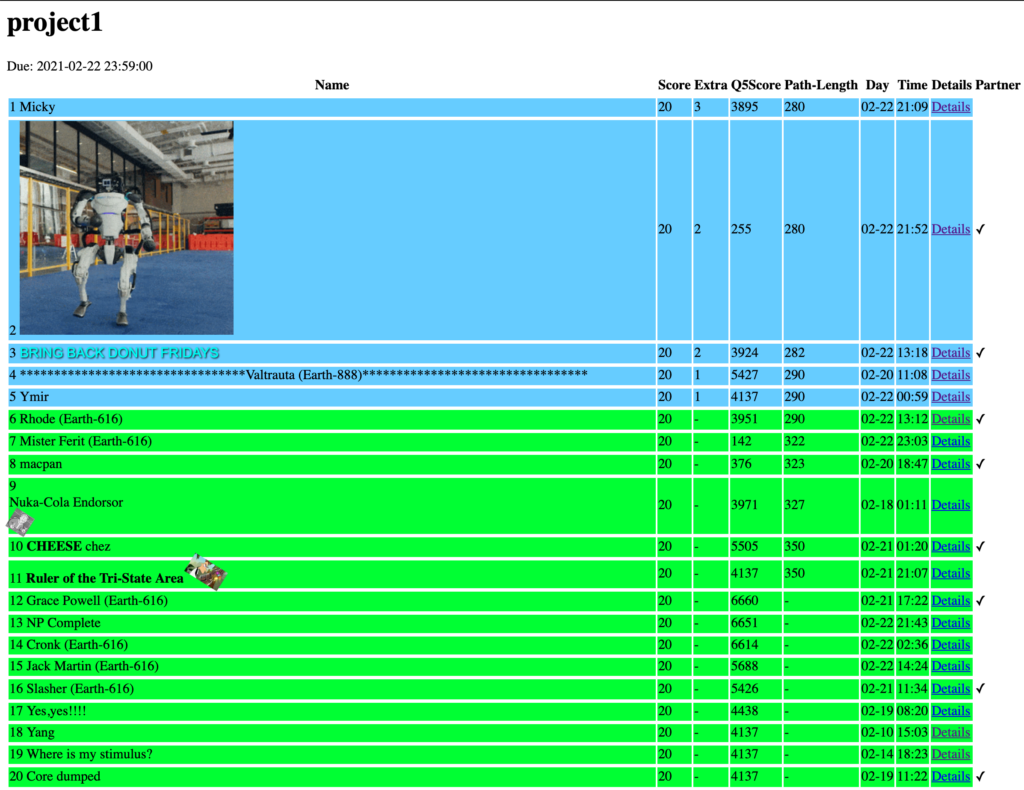
In my AI class this semester, we have a 3-part course project based on the Berkeley CS118 Pacman Project. The first part of this project was due last week, and we were asked to implement some straightforward search algorithms like DFS and A*. However, the interesting part of this project was an optional question of the assignment, where we were asked to find the best solution we could compute on a Pacman version of the Travelling Salesman Problem, by implementing a custom algorithm in only 30 seconds of computation time. The top solutions in the entire class would get a few points of extra credit!
In this post, I'll show how I got to the top of my class's leaderboard, without actually needing to coming up with a new algorithm of my own.

Greedy Algorithm
Looking at the above image, one objective might be to find the shortest possible path to eat all the dots on the board. However, this state space is far too large to apply a perfect algorithm like BFS or A*, it would take enormous amounts of processing power/time. Instead, the correct approach is to find an approximate algorithm which finds a near-optimal path.
The last question of the homework has us implement such an algorithm, where Pacman simply approaches the closest dot in a greedy manner. Using this algorithm, we are able to find a path to eat all the dots in 350 steps. This is a very sub-optimal algorithm though. In states where there are multiple closest dots (for example the starting position), Pacman deterministically chooses one dot based on the initial ordering definition. This means that, in many (most?) situations, Pacman chooses the objectively wrong dot to go towards.
In the following image, you can see the consequences of choosing the wrong dot. Instead of systematically eating dots in the map, Pacman leaves groups of dots by themselves. In fact, the rightmost dot in this image is the last dot in Pacman's overall path, adding dozens of extra steps to the path just because we didn't eat the dot when we were right next to it.

Randomized Greedy Algorithm
In the extra credit assignment, we were asked to come up with a better approximate algorithm than the greedy "eat-closest-dot" algorithm. The catch was that we only had 30 seconds of computation time, so we couldn't just run A* for hours on end waiting for the perfect solution.
I was sure that others in the class would be able to come up with very smart algorithms to get near-optimal results. However, I was quite lazy. While I wanted to win, I didn't really want to take the time and come up with a fancy algorithm. Instead, I created a simple algorithm - I randomized the greedy algorithm from before so it was no longer deterministic, and simply ran it over and over again for 29 seconds. In the end, I returned the best path found.
# Pseudocode for the Randomized Greedy Algorithm starttime = time.time() while True: if time.time() - starttime > 29: break newpath = getRandomPath(state) # Find-closest-dot path if len(newpath) < len(bestpath): bestpath = newpath return bestpath
Because the initial greedy algorithm only takes a fraction of a second, I'm was actually able to generate several hundred paths. The results weren't super constant because of the inherent randomness, but I was able to consistently get paths under length 310, with 296 as my best result. I submitted this only a few days into the competition, and this result was at the top of the leaderboard for the majority of time the board was active.
Running BFS on Generated Paths
A few days before the deadline, I came up with a potential improvement to the algorithm. Instead of simply taking the best path found, I combine all of my paths into a single directed graph, and run BFS on this graph to find the best, combined path. The intuition behind this is that each of my randomly generated paths is probably going to be pretty bad, but by combining them, we can perhaps pick and choose the good elements of each path to get a new path.

For example, each of the random generated paths would usually end up on one of the two sides (like the above image) where there was a lot of room to go wrong, thanks to the large areas of food. While the best path would probably have a bad solution to this specific end state, it would be very likely that a different random path had a better solution, and we could just cut and paste the better solution into the otherwise best path found. We can use similar logic for the beginning of the path as well.
# Pseudocode for the Randomized Greedy Algorithm, Graph Version
starttime = time.time()
while True:
if time.time() - starttime > 23: break # Lowered time to 23 because of post-processing requirements
newgraph = getRandomPath(state) # Find-closest-dot path, converted to an adj. graph
for k,v in newgraph.items():
if k in graph: graph[k].append(v)
else: graph[k] = [v]
paths.add((k,v))
return BFS(graph, hash2(state)) # BFS from the start stateThe only hiccup with this approach was that I was storing the graph as an Adjacency Dictionary (for ease of computation), but storing the state object itself slowed the process a lot. I had the idea to just store the hashes of each state object, but it turns out the hash function for state objects that we were given was terrible, and I needed to guarantee that there would be no collisions in order for the graph to work. Instead, I just wrote my own hash function (actually returned a tuple), which didn't give me any collisions.
def hash2(state): return (hash(state.data.agentStates[0]), hash(state.data.food), state.data.food.count())
Using this algorithm, I was able to improve my best result to 286! I was hoping that this would be enough to win the entire competition. Alas, with less than a day to go, two teams surpassed my score and got to 284 and 282, respectively 😢. Looking into their submission details, it was clear that these teams had developed better algorithms for finding the best path. Both of their submissions ran in under 2 seconds, while my submission took over 29.5 seconds to run. At this point, faced with superior algorithmic technique, what did I do? Did I go back to the drawing board to try and come up with my own smart algorithm? No, I just decided to work even harder! (or make my computer work harder, at least)
Python Multiprocessing
My last idea was to implement Multiprocessing, so I could generate paths on multiple threads inside Python. Actually, the Multiprocessing module inside Python 2.7 was quite lacking compared to the 3.x Python that I'm used to. I had to put my above code inside of the class __call__ method for some obscure reason that I found on StackOverflow, and pass the object itself into my Pool, but it worked in the end.
# Code Snippet to implement Multiprocessing
p = Pool(8)
all_paths = p.map(self,[state]*8) # Refers to code from above
for path in all_paths:
for (k,v) in path:
if k in graph: graph[k].append(v)
else: graph[k] = [v]
return BFS(graph, hash2(state))Using Multiprocessing, I was able to generate about 5x as many paths as before in the same 30 second time limit! As a result, I improved my best result to 282.
The 284-scoring team also brought their path down to 282, so at this point, I was expecting there to be a three-way tie for first. However, a few hours before the deadline, one of the teams managed to improve their own algorithm to 280. My response was to re-submit my code a few more times to the autograder, and the RNG gods eventually blessed me with a 280 score as well. In the end, I tied for first in the class.



0 Comments