One of my current research projects deals with applying elements of Curriculum Learning (CL) for designing real-world human learning curricula. In the last few weeks, I've read a number of CL papers, and in this blog post, I'll summarize two of them. The first is the "original" paper on this topic - Curriculum Learning, by Bengio et al., and published at ICML 2009. The second is a survey paper, aptly titled Curriculum Learning: A Survey, by Soviany et al., IJVC 2022.
Curriculum Learning, Bengio et al. (ICML 2009)
This paper starts with an observation of real human (and animal) learning, where it's been shown that learning is accelerated when the order of examples presented is organized in a meaningful order, rather than randomly. The authors then aim to tie this observation to neural network learning. This is clearly an important problem because learning NNs is a difficult task, especially in 2009, so any potential improvement in learning methodology should be investigated.
First, the authors formalize what they consider a curriculum in the context of machine learning. Essentially, they define a curriculum a sequence of distributions where the entropy of the distributions increase. Intuitively, this means that the distributions (of training data) get harder as time goes on. At this point, the authors note that actually defining what it means for a data point to be "easier" to learn isn't obvious, and could depend on the task domain.
First, the authors look at a simple model, learning a linear SVM classifier. They first show that just learning a model with easy examples (ignoring points which fall on the wrong side of the Bayes classifier) leads to statistically better performance than training on all points (16.3% vs 17.1% error).
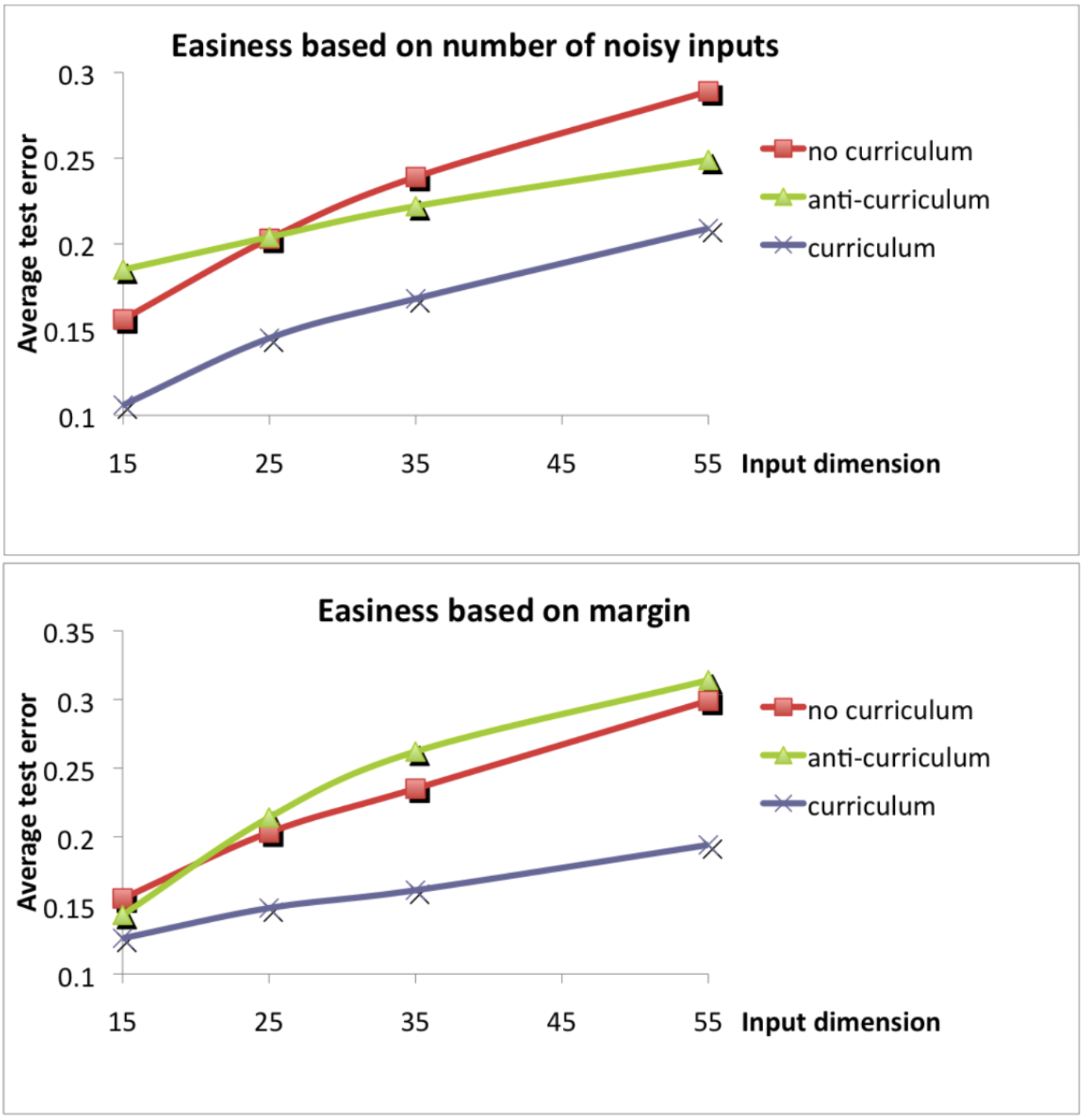
Then, the authors look at training a perceptron linear classifier. They define two different metrics for data ease - how noisy the data is, and how far a point is from the true margin. They find that in both cases, learning in the order of easy to hard leads to better performance than learning from hard to easy, or learning in a random order.

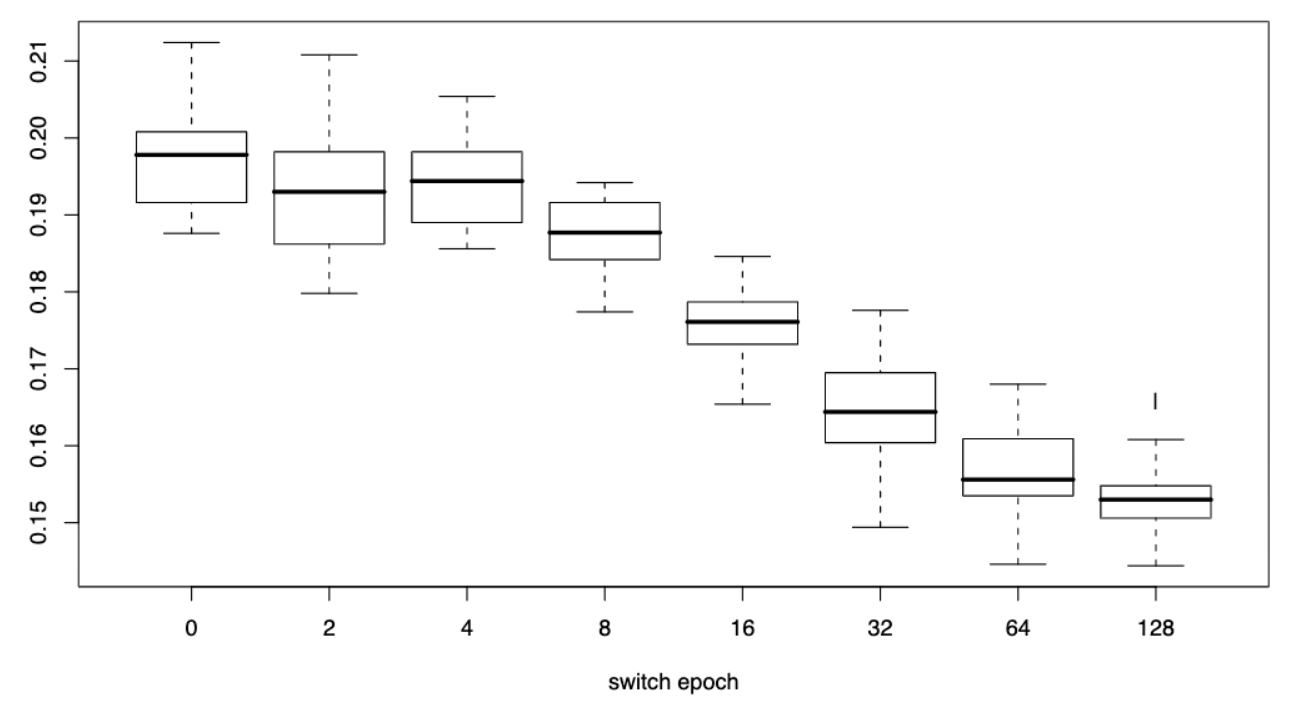
Next, the authors look a simple computer vision problem - recognizing rectangles, triangles, and ellipses in a 32x32 pixel image. In this domain, ease is defined by the "shape" of the shape, where easy shapes are squares, equilateral triangles, and circles. They evaluate a two stage design, where over 256 epochs, they train on just easy examples for the first n epochs, and train on harder images for the remaining 256-n epochs. Overall, the results show that the more epochs consist of easy examples, the better the overall performance is. However, it is a little unclear why the authors stopped at 128 epochs, rather than continuing to increase the switch epoch to see where performance starts to decrease
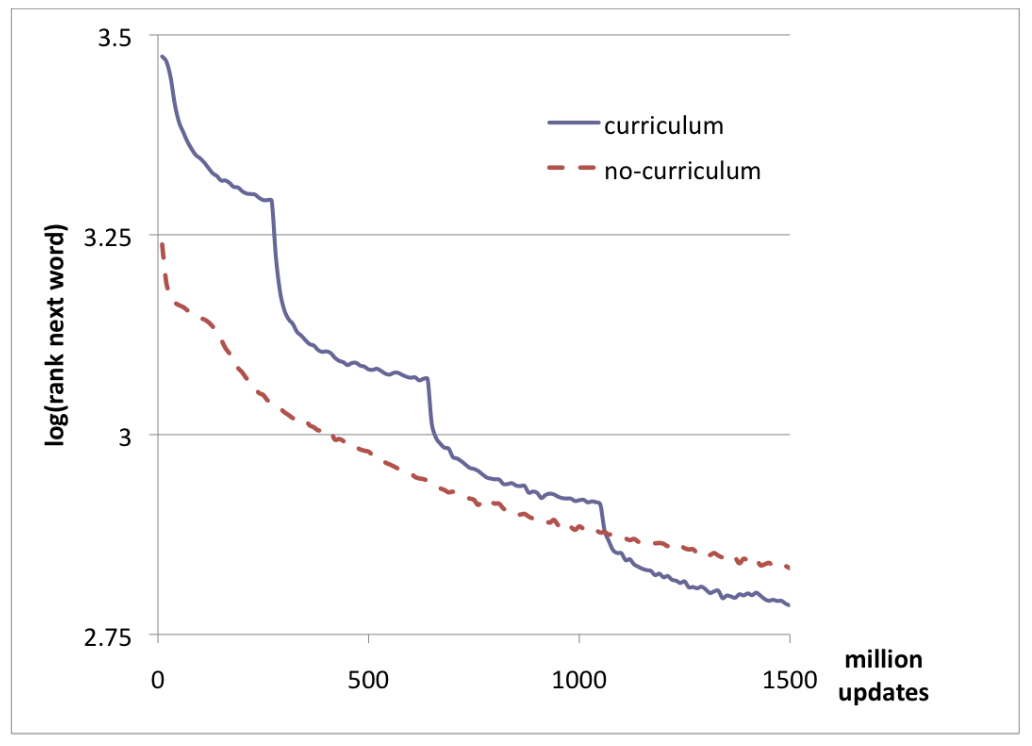
Finally, the authors look at a more challenging problem, training a language model. In this example too, they find that using a curriculum, defined by the frequency of the word (if the word is in the 5k most common words, 10k most common words, etc) leads to better converged better. It should be noted though that the performance is worse at first, presumably because the model missed out on the majority of words at the beginning of training.
Overall, this work shows that the idea of curricula shows promise for training neural networks through the use of examples in four different domains. However, the authors leave it to future work to better understand , and the authors leave it to future work to better understand how this process actually works, and demonstrate this in more domain examples.
Curriculum Learning: A Survey. Soviany et al. (IJVC 2022)
In the 15 years since the original curriculum learning paper came out, there has been a lot of work done in the space of CL, and this was recently summarized by a survey paper published last year. I won't go over most of it (it's 43 pages!), but I'll try to give a sense of the space that we're in now.
The paper starts off by summarizing what CL is, giving a motivation for its example, and goes over the Bengio paper. Since I already did that above, I can skip rehashing this section.
The key thing that this survey paper tries to do is relate the idea of CL (changing learning over time) to the different aspects of machine learning itself. They give this definition of ML which I've seen in a lot of places.
Definition 1: A model M is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T ,as measured by P, improves with experience E.
The authors then say that the idea behind CL can be applied to each of these aspects. Namely, CL applied to the Model-space means changing the model architecture during training, CL applied to the Experience-space means changing which experiences (i.e. data) the model learns during training, CL applied to the Task-space means changing which tasks are being solved during training, CL applied to the Measure-space means changing how we quantify model performance (e.g. the loss function) during training.
They then summarize a taxonomy of CL applied to different areas. Vanilla CL was introduced by Bengio, and exploits a set of a priori rules to discriminate between easy and hard examples. In Self-Paced Learning, the order is not determined a priori but computed dynamically based on performance. Self Paced CL is a combination of Vanilla CL and SPL, where the order is jointly determined by a priori rules and performance. Balanced CL ensures that harder samples are balanced under defined constraints (e.g. ensuring class labels are balanced equally). Teacher-student CL adds an auxiliary model which determines learning parameters for the student.
The authors then describe over 100 CL papers over the last 15 years, categorized by domain application and CL taxonomy, in a 6-page table and 20 pages of text. I'm not going to go over this, you can read the paper if you'd like more detail :).
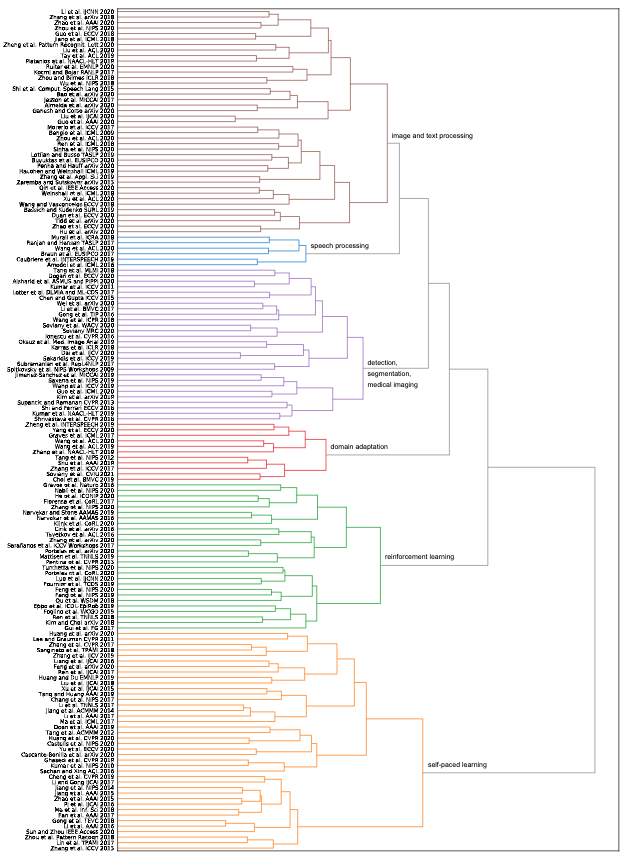
They then use this analysis to create an automatic hierarchy of CL papers using a TF-IDF clustering agglomeration. This is a fancy of saying they find out which papers share similar words to each other. Papers with more similar words are deemed to be more similar in content as well. They find that TF-IDF produces a similar hierarchy to the manual (subective) one they defined, providing good evidence for their analysis.
Overall, I feel like I have a much better understanding of CL than I did before these papers, and hopefully you do too! I think I'm going to try and do more blog posts in this style, where I go over a big area of work, by explaining a pioneering paper which introduced the field or make some breakthrough, and summarizing a survey paper which has looked at advancements since. I already have a second post in the works following this format, so expect to see that out shortly.



0 Comments