My second rotation has started on Monday, and I've decided to work with Dr. Chenyang Lu in the area of Machine Learning for Health. During the rotation, I'm going to be working especially close with York Jiao, MD, the Director of Anesthesia at the Shriners Hospital for Children in St. Louis. In between all of his medical jobs, he spends his time writing Machine Learning papers! The plan for my rotation is to work on the same project as one of his recent papers - Probabilistic forecasting of surgical case duration using machine learning: model development and validation, and see if I can find any potential improvements to the model!
I have another paper review that I need to submit for the rotation, and just like last time, I'm planning on writing it in the form of a blog post! As a reminder, the three components of my paper review is a summary of the paper, an explanation of the paper's novelty, and critique of the paper. Let's get started!
Summary
The paper starts off giving the motivation for this research. Every day in hospitals, surgeries are scheduled to take place in operating rooms. This scheduling problem is very important for ensuring that the hospital staff and resources are used efficiently. Traditionally, surgery duration are estimated based on the surgeon, but these estimates can often be inaccurate, leading to worse hospital outcomes. For example, if a surgery is scheduled to take 3 hours but actually takes 5, this pushes back all the other surgeries that were planned during the day. On the other hand, if the surgery only takes 1 hour, there would be two hours of lost potential usage time.
Next, the authors go over prior literature in this area, and their limitations. Part of these limitations are due to the types of data trained on, so the authors also discuss the datasets that they use. In addition to the more typical numerical and categorical data, the dataset notably contains unstructured textual data.
The most important section of the paper discusses how the model was trained. The model itself looks like the below image.
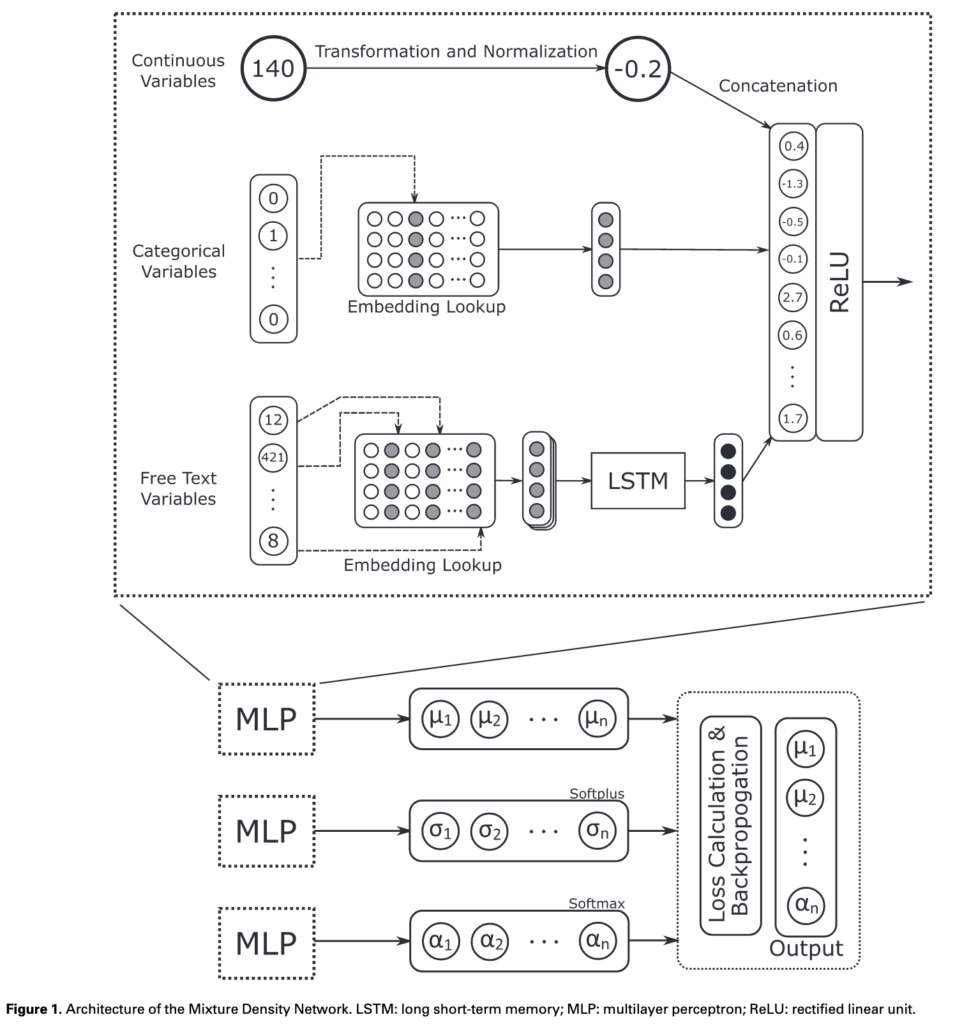
The continuous and categorical are normalized and combined as inputs for the model. The unstructured text data is broken up into word tokens and embedded into a vector. After running these word embeddings through an LSTM, the output is concatenated with the other data to be used as the input to the Mixture Density Network. I'm personally not very familiar with MDNs, so I'll have to do some more reading on how these work. MDNs were developed by Bishop in 1994, and York made a comment that replacing the MDNs with a more modern architecture could be an option for improving the overall output. In any case, I'll need to really understand how MDNs work before I can decide to use something else.
One of the key aspects of model training was the performance measure chosen - continuous ranked probability score (CRPS). This measure was chosen for several reasons - it combines multiple predictive qualities into a single value, it rewards more precise predictive distributions, it is measured in minutes for ease of interpretability, and it can be calculated for any forecast with a probability distribution.
Finally, the paper details the results of the model. Testing against other ML models like Gradient-Boosted Decision Trees, Random Forests, Bayesian Method, and standard Decision Tree. The MDN model also significantly outperformed the scheduled operation times. When testing a subgroup of data, rare cases, the authors also found that the MDN model outperformed the other models as well. Permutation importance was calculated on the features as well and the results are in line with previous work.
Novelty
The paper introduced several novel features for this application. The most important of course is the use of a Mixture Density Model. As a result, the model is able to predict not only the mean operation time, but a distribution of potential times. This is important not only because it happens to be more accurate than the other methods, but it provides more relevant information which can potentially take cognitive load off of the scheduling decision-makers (according to Jiao).
Inside of the model itself, two novelties include the use of free-text features (parsed using an LSTM) and the use of CRPS as the primary performance measure. The NLP parsing ended up being very important, since final results showed it as the second most important feature of the model overall.
The other main novelty of the paper was the dataset itself, since it is much larger than the data used in prior studies.
Critiques
Overall, I thought the paper was quite good, and especially impressive considering the background of the authors. The authors defined and justified their problem very well, and implemented a novel solution to the problem with great results.
I think my biggest critiques of the paper are the technical explanations behind the model. The most egregious example this is the Mixture Density Networks itself. The authors introduce the model by saying that "One neural network was trained: a mixture density network (MDN)." However, there isn't any real explanation on what an MDN is, how it works, or why it was chosen as a base model over other models. The authors also don't give any explanation on how the model was implemented, other than mentioning that Tensorflow was used. Since the audience for the paper are people with prior background in machine learning, the authors probably don't need to explain more basic terms like ReLU or MLPs, but I would have definetly appreciated at least a paragraph explaining MDNs, since it's really the key idea behind the entire paper.
There are a few places where I wish there would have been more technical details. For example, describing the prior models which are used as a benchmark (DT, RF, GBT, Bayes). There doesn't need to be as much explanation since it isn't the main point of the paper, but maybe a sentence or two on each would be nice.
More explanation on LSTMs would have also been useful. How was the LSTM model trained and how were the word embeddings generated? Especially since the NLP section of the features turned out to be so useful, I would have liked more explanation on how the LSTM worked, and perhaps some details on LSTMs for a general audience that isn't as familiar with them. I'm personally not the biggest expert on NLP, but I've seen that LSTMs and RNNs in general are starting to be phased out in favor of other NLP models like BERT and GPT. Perhaps this is another avenue of potential improvement for the model.
Conclusion
Overall, I thought this was a great paper. I'm really excited to work with York and Chenyang over the next month to work on this project, and hopefully introduce some of my own improvements into the model :). I'm going to be meeting with York soon to get his thoughts on the model, and start looking at the actual datasets and code which was used in the paper. Also, I'm going to be giving a brief talk on this paper tomorrow at the CPSL seminar tomorrow, and there'll also be some brainstorming so I can get other more experienced people's thoughts on the paper.
See you all next time!



1 Comment
Implementing Closed Form CRPS in Python – Saumik Narayanan · November 29, 2020 at 10:23pm
[…] my review of the paper Probabilistic forecasting of surgical case duration using machine learning: model […]