Digitizing Chess Scoresheets Project
In competitive chess games, players must keep a score of the game as it is played. Notating a game like this is required for two reasons. The first is that it helps tournament officials manage player disputes in cases like 50-move draw or 3-move repetition. The second and more important reason is that it allows players to analyze the game after to learn from their mistakes.
However, more and more chess analysis is taking place on a computer, which requires converting the game from a paper list of moves into a digital record of the game. In addition, this allows players to keep all of their games in one place, allow for easy backing up of their game history, and creating digital files for sharing with others. However, while entering games is not a very lengthy process, it can be quite tedious.
My goal is to build a tool which can take in an image of a chess scoresheet, and automatically convert it into a digital record of the game, so that users can immediately start analyzing the game. There already exist lots of tools which use computer vision for extracting information from specialized documents, like invoices or mobile check deposits. The biggest question is if I can learn how these tools work so I can implement it for my own use case.
I’ve actually had this idea floating around in my head for several years, but I figure that now is the perfect time to try to create it, since I’m relatively free, and I’m already taking online machine learning courses. Even if I’m not able fully finish the project, I would like to simply use this project as a reference point to guide my learning and give me something to work on when I feel stuck.
I have already started some preliminary work for the computer vision side of the project, but I don’t really have anything to show yet. Instead, I’m going to spend the rest of this blog post describing and analyzing a simple algorithm I built in Python for processing the data after I’ve extracted from the image.
Finding Missing Moves Algorithm
When analyzing prior games from a scoresheet, one very common challenge faced especially by new or scholastic players is when there is an error in the chess notation. Maybe the player forgot to notate a pair of moves [efn_note]In chess, normally a move refers to a pair of two moves - one for White, and one for Black. The term ply is used for a single half-move. However, in this post I will be using the term move to refer to half-moves, as the term ply is more unknown to general audiences.[/efn_note], or the player’s handwriting was illegible for a certain move. This can cause significant issues when analyzing the game afterwards.
For example, a player might be trying to analyze their 60-move game but skipped notating for both sides on moves 12 and 13. If the player can’t remember what these moves were, it essentially invalidates the remaining 47 moves, as the player won’t be able to analyze these moves as well.
One solution might be to just try to make random moves on move 12 just to continue getting through the game. However, if they pick the wrong move, not only will the analysis be flawed for the rest of the game, they might not even realize they picked the wrong move until far in the future, when they realize a position or move is illegal. This would be a massive waste of time!
To solve this problem, I’ve developed a simple algorithm which can determine what the missing move in a game notation is, based on the legality of future moves. Better yet, the algorithm will still work if there are multiple missing moves, with the limitation that the code becomes exponentially slower with more missing moves. Below, I describe what the algorithm is, and then I will give a simple example showing how this code works.
Description of Algorithm
- The algorithm takes in a list of moves, which each move represented as a Algebraic Notation string, and missing moves represented as None values.
- The algorithm initializes the initial board state of a chess game.
- The algorithm iterates through the list of moves. At each move, there are 4 possible options for what the next move could be:
- The next move is marked as missing (i.e. the value of the move is None). In this case, we first find a list of possible legal moves in the current game state. Then, we iterate through each of the current legal moves to find if any of them are compatible with the following moves, meaning that they create a possible game state. We can find if they compatible with the remaining moves by branching the game state and noting which moves returned a full game state. We then concatenate all of these lists together and return a list of lists as our final result. This explanation may not make sense at first, but hopefully it will after we go through an example below!
- The next move is a valid legal move. In this case we simply play the move on the board and continue iterating through the list.
- The next move is not a valid legal move. In this case, we break and return an empty list.
- There is no next move as we have reached the end of the list. In this case, we simply return the full list of moves.
- The algorithm returns the list of all accumulated move lists as valid branches. In an ideal scenario, there is only one list returned, so the user knows exactly what moves were played. However, with more ambiguous inputs, there may be multiple move lists returned, or even no move lists returned if the input was "wrong" in some way.
Algorithm Code
Below I show my implementation of the code to serve as a reference while reading through the walkthrough. All chess-specific calls I have to make, including updating the board, checking legal moves, and getting the current board state were done through the python-chess library.
import chess
import copy
def find_valid_move_lists_helper(starting_fen, starting_move, move_list):
valid_move_lists = []
board = chess.Board(starting_fen)
for i in range(starting_move, len(move_list)): # Iterate through all moves in the game
if move_list[i] is None: # Case 1: Current move was marked missing
chess.svg.board(board)
legal_moves = board.legal_moves
for j in legal_moves:
current_list = copy.deepcopy(move_list)
current_list[i] = board.san(j)
valid_move_lists += find_valid_move_lists_helper(board.fen(), i, current_list)
return valid_move_lists
else: # Current move
try:
board.push_san(move_list[i]) # Case 2: Current move is valid
except Exception as e:
return [] # Case 3: Current move is invalid
current_list = copy.deepcopy(move_list)
return [current_list] # Case 4: Reached end of move list
def find_valid_move_lists(move_list):
starting_fen = chess.Board().fen()
return find_valid_move_lists_helper(starting_fen, 0, move_list)Algorithm Walkthrough
Let us demonstrate the algorithm with a simple example, using the input list ['e4', 'e5', 'Nf3', 'Nc6', None, 'a6', 'Ba4']
Readers who play chess competitively will know this line as the Ruy Lopez, one of the most popular openings in the history of modern chess. If this is you, I’m sure you already know exactly what the 5th move should be. However, if you don’t play chess, that’s fine, it’s what we have the algorithm for!
The algorithm starts by taking in the above move list and iterating through the moves. The first four moves are all valid moves, and as a result, we get the following game state:

At this game state, it turns out there are 27 legal moves: Ng5, Nxe5, Nh4, Nd4, Ng1, Rg1, Ba6, Bb5, Bc4, Bd3, Be2, Ke2, Qe2, Nc3, Na3, h3, g3, d3, c3, b3, a3, h4, g4, d4, c4, b4, and a4.
At this point, the algorithm iterates through all 27 possible branches and tries to finish the game. In the first iteration, the algorithm will attempt to validate that ['e4', 'e5', 'Nf3', 'Nc6', 'Ng5', 'a6', 'Ba4'] is a legal sequence of moves. Unfortunately, Ba4 is not a legal move with the first six given moves. Then the algorithm will try ['e4', 'e5', 'Nf3', 'Nc6', 'Nxe5', 'a6', 'Ba4'], and so on, until it has gone through every list of legal moves.
It turns out in this case that Bb5 is the only move which causes the entire list of moves to be valid, something that any competitive chess player could have instantly told you!
Analysis of Runtime
While this seemed simple enough, the issue with this algorithm is as there are more and more missing moves, the runtime of this grows exponentially, since each missing move will create a split that will create more and more new branches. Since the algorithm’s runtime isn’t immediately obvious, I wanted to try for myself a few examples before diving deeper into the code to determine what the actual runtime was.
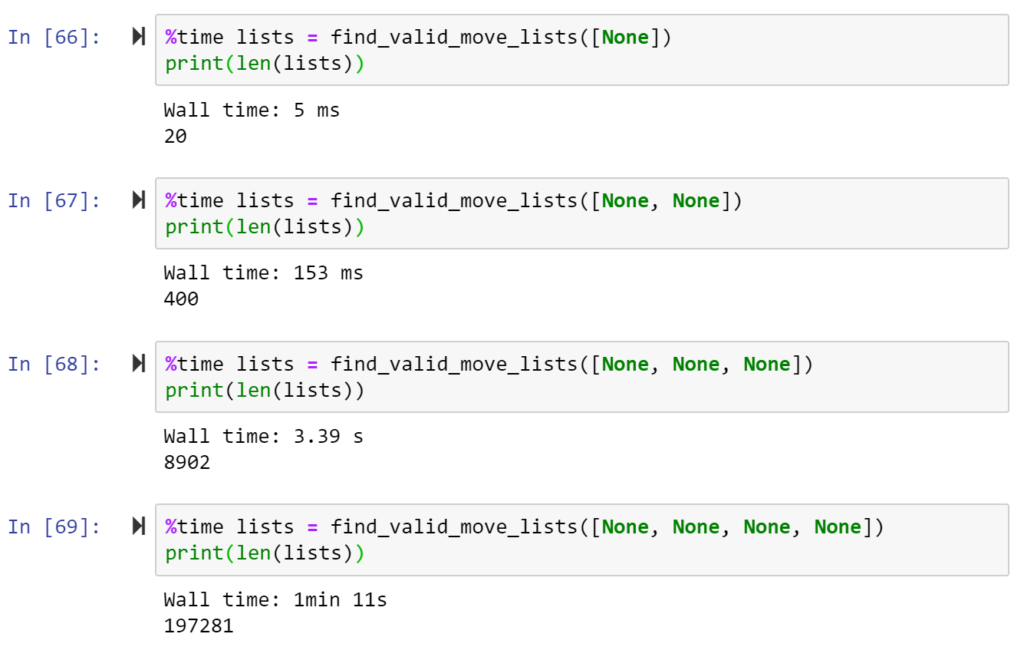
Just for fun, I used this algorithm to find the number of legal games after 2 moves for both White and Black. In the initial game state, both White and Black have 20 legal moves, and no move White can make will affect Black’s legal moves. Thus, we see that there are 20 possible “games” after one move, and 400 possible “games” after two moves. After this though, we begin to see this number increase with an even larger branching factor. There are 8902 possible games after three moves, meaning that the average branching factor on move 3 is 8902/400 = 22.26. On move 4, there are 197281 moves, meaning an average branching factor of 197281/8902 = 22.16 moves. Fun fact: out of these 197281 moves, exactly one of them actually ends in checkmate!
Along with the number of games increasing exponentially, we see that the runtime is also increasing exponentially – from 5 milliseconds to 153 milliseconds to 3.39 seconds to 71 seconds in just four moves! Looking at the increase in runtime from iteration to iteration, we see multiplicative increases of 3100%, 2216%, and 2094%. This number is somehow decreasing, but I can’t see if this trend continues since I don’t have time to keep running my algorithm like this! If I continued for another move, it would take around 20 minutes, and going up to six moves might take over 6 hours!
Fortunately, we can look at the runtime another way, by analyzing the algorithm itself. In order to do this, we need to consider three parameters: the number of moves in the chess game, the average branching factor per move, and the number of missing moves. We denote these numbers as n, b, and k, respectively.
At each split, the number of branches will be increased by a factor of b. Let's say b=3. Then, with 0 missing moves, we have 1 branch, 1 missing move gives us 3 branches, 2 missing moves gives us 9 branches, 3 missing moves gives us 27 branches, etc.. For each branch, we have to go through every move in the branch to determine if the total branch is valid, so we get a runtime of O(n*bk).
Actually, with the way the algorithm is set up, we don’t have to go through every move in the branch, only the moves after the branch splits. However, this makes no difference to the runtime, since we can’t make assumptions on where the branch is splitting in the tree.
We can now specify this runtime even further by using existing knowledge of a chess game to determine the actual branching factor. Chess doesn’t have a set branching factor, as each position has a varying number of legal moves. However, user kentdjb on chess.stackoverflow.com looked through 2.5 million games from ChessBase, and found an average branching factor of 31.1. Depending on the position, there could be as many as 218(!) child branches, although we should realistically never get close to this number.
Using this information, we can give our algorithm an average runtime of O(n*31.1k), and a worst-case runtime of O(n*218k).
Conclusion and Next Steps
In this blog post, I have introduced my main personal project that I am pursuing over this summer – converting an image of a chess scoresheet to a digital scoresheet of the game. I also described my first step taken on this project – building an algorithm to find missing moves in a chess scoresheet. While they do say that “A journey of a thousand miles begins with a single step”, in this case, the first step is quite tiny, and I have a long road ahead. I was able to write this algorithm in a day, but my steps ahead are going to be much more challenging.
In no particular order, I will have to learn about Image Segmentation in order to extract a table of chess moves from a scoresheet, learn about handwriting recognition to convert the written moves to digital moves, and build a dataset containing images of scoresheets along with labels of the final notation, since I couldn’t find one that already exists. When I want to deploy my project, I will have to learn about either Web Development or Mobile App Development, although these are so far away that I’m not worrying about that right now :).
If I don't get through all of these stages that's fine, as long as I'm happy with with I've learned while working. Hopefully I will continue to make progress on this project, and I will give you all more updates when I hit new milestones.
See you soon!
Saumik
Header Image by Heritage Auctions



8 Comments
michael · June 21, 2019 at 9:34pm
you could probably achieve better space complexity (and average time complexity!) using a bidirectional breadth-first search rather than a depth first search
Saumik · June 21, 2019 at 11:00pm
Actually I spent a lot of time at first trying to go backwards to save on space and time, I just couldn’t find a way to make it work since the possibilities for moves at a current game state depends on the previous moves. If you have any thoughts on how I could implement this though, let me know!
Anthony · June 21, 2019 at 9:37pm
So this is like a depth first search brute force? Why not prune out options for pawns since before None states and after None states you can see the change in states for the pawns. Since pawns cannot go back to previous position you can rule out all the pawn moves if the before None state and after None state for pawns are the same. Just something to think about 😉
Saumik · June 21, 2019 at 10:44pm
How do you suggest I find the change in states for the pawns? There is no way to get the state of the position after the missing move without making an assumption about that missing move. Additionally, because pawns can switch files, I can’t really make assumptions about where pawns are at future moves by checking all future pawn moves on that file. Maybe there is a way to prune moves by looking at future moves, but it would probably be pretty complicated to check for all the cases. It’s definitely an interesting option to think about though!
Anthony · June 21, 2019 at 10:53pm
Oh I see, you only keep track of the moves made not the state of the pieces or the board. Hmm yeah that would make it difficult to prune out and the bidirectional breadth-first search would not work either.. I guess its a matter of trade off between space complexity and time complexity. How would keeping track of entire board rather than just the moves help improve the accuracy and time of finding missing moves? Interesting.
Saumik · June 21, 2019 at 11:05pm
It’s not that I only keep track of the moves and not the board state, it’s that I am not given the board state at any move except the first move. The only way I can construct at a board state at any later move is by making an assumption about the missing moves beforehand, which is what I do during the branches.
Kenneth · March 24, 2023 at 10:18pm
Hello, sorry about replying on an old post – how did the rest of this project go?
Saumik · March 28, 2023 at 5:31pm
Lol, it totally did not happen. Though with the state of computer vision, this absolutely can’t be a hard project to do, I just haven’t had time to do it, and I’m surprised nobody else has either.