Unlike many other PhD programs, WashU has a special rotation program to facilitate student-advisor matching, where students do a 2-4 one-month research stints with professors so the students and professors can get to know each other better before committing to a relationship for the next 4+ years. On Wednesday, I started my first rotation with Dr. Chien-Ju "CJ" Ho, and the topic of the rotation will be on Learning Fairness Criteria and Biases in Inverse Reinforcement Learning.
To start off the rotation, CJ gave me several papers to read through, so I can become more familiar with this area of research. In this post, I’m going to go through each of these papers, and give a quick summary about the findings of the paper. I’ll also give some domains and problems I’ve brainstormed which may be applicable or related to the topics of these papers.
Algorithms for Inverse Reinforcement Learning
This paper was written in 2000 by two legends in the field of AI: Andrew Ng and Stuart Russell, though Ng was still in grad school when this paper came out. Essentially, paper turns the methods and goals of Reinforcement Learning upside down. Normally in RL, we are concerned with creating a Policy to maximize an Agent’s Reward function as it executes Actions to navigate through a domain of potential States - a framework called the Markov Decision Process. To put this more simply, we are given a list of goals, and we have to figure out what actions to take to accomplish these goals.
One example of this process is a game like Super Mario Bros. The agent is Mario, actions are things like moving up/down/left/right, and states are the locations of blocks, enemies, pipes, etc. In Super Mario Bros, the main reward would be completing the stage itself, but there are also secondary rewards like collecting coins and defeating enemies, and even negative rewards (like losing lives). There are plenty of other real-world examples of RL, in gaming, robotics, or even advertising (where the reward could be number of clicks).
After introducing RL, Ng and Russell go through some of the math behind how RL works, describing elements like Discount Factors, Value Functions, Q-Functions, and Bellman Equations. I’m not going to go into the specifics of this here but knowing how this works is definitely necessary in order to understand how to improve it for more complicated domains.
Inverse Reinforcement Learning tries to do something completely different from standard RL – instead of trying to learn how to do a task well to maximize a known reward, we watch a optimal agent performing a task, and try to figure out what they are trying to do (learn what the optimal agent’s reward function is). This may seem useless at first, but as we’ll see, this is very important for teaching AI systems to do new tasks which are hard to articulate precisely. For example, if we want an autonomous vehicle to “drive well”, how does the system know what that even means? Instead of programming actions for every conceivable scenario, a simpler option could be to give examples of “good driving” by humans, and have the car learn from the examples.
The paper goes into more depth on how IRL works, giving linearly satisfiable equations to satisfy, how to deal with very large state spaces, and how to use simulated policy trajectories. The paper also shown some simple experiments in which IRL works well. Overall, this was a pretty interesting paper to read. I’m still working on understanding some of the technical details myself, but it’s a good start.
Learning the Preferences of Ignorant, Inconsistent Agents
While standard IRL, as explained in the previous paper, is very promising, it relies on one key assumption, that the agent we are watching is acting optimally in the agent. As the saying goes, Practice doesn’t make perfect – perfect practice makes perfect. If we’re trying to learn from an agent that somehow deviates from optimality or exhibits systematic biases (like every single human on earth), then we shouldn’t just copy the subjects exactly, we want to learn how the agent is biased, so we can better learn what the agent’s initial reward function was.
This 2015 paper, by Evans, Suhlmuller, and Goodman, examine optimality deviations in this paper – state uncertainty and temporal inconsistency. Uncertainty is self-explanatory concept, while temporal inconsistency means that that humans often make plans that they later abandon. A famous behavioral example of this is that people generally prefer to take $100 today over $110 tomorrow but prefer $110 in 31 days over $100 in 30 days. This makes no sense, but that’s how humans are! In the paper, the authors create several suboptimal agents that exhibit these tendencies, and then create an IRL model that still works on these agents.
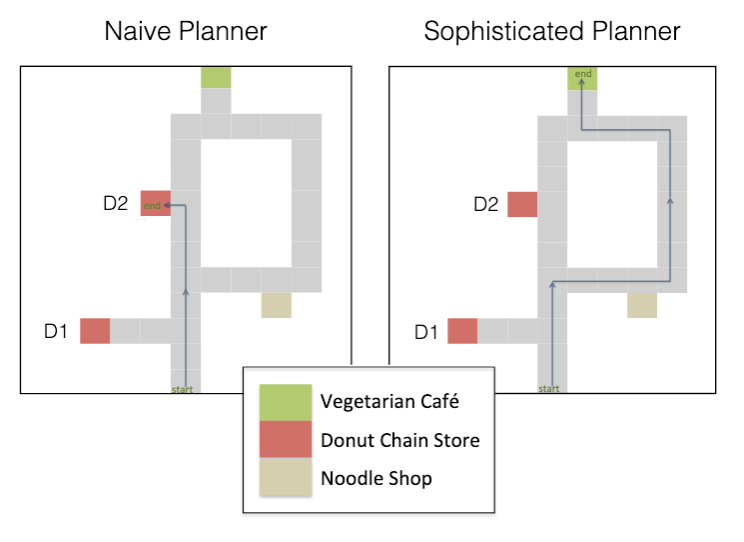
This picture shows two suboptimal agents which suffer from temporal inconsistency. Initially, both agents want to go to the vegetarian café, which would maximize their reward for this instance. However, as the naïve agent heads directly towards the café, it is tempted by the donut café (who wouldn’t pick donuts now over veggies later?) and abandons its original plan. The sophisticated planner understands its own bias and chooses the longer route in order to avoid the donut shop that it knows it will be fatally tempted by.
The paper also covers examples with uncertainty (e.g. the agent tries to go to the noodle shop, but finds out later that it’s closed), and learning from multiple examples, and goes over the equations on how to model these.
Using to this new knowledge, the paper’s new IRL model is not only able to figure out how an unknown agent is biased, it can still recover an estimate of the initial reward functions were. Results from the model are then compared to surveys done with human subjects, who are also tasked with figuring out what agents are trying to do.
Future work mentioned include applications on more realistic domains and evaluating algorithms without using human inferences.
On the Feasibility of Learning, Rather than Assuming, Human Biases for Reward Inference
This third paper takes things to an even higher level. As stated in the title, instead of assuming human biases (like the second paper did), Shah et al. are interested with learning the biases directly.
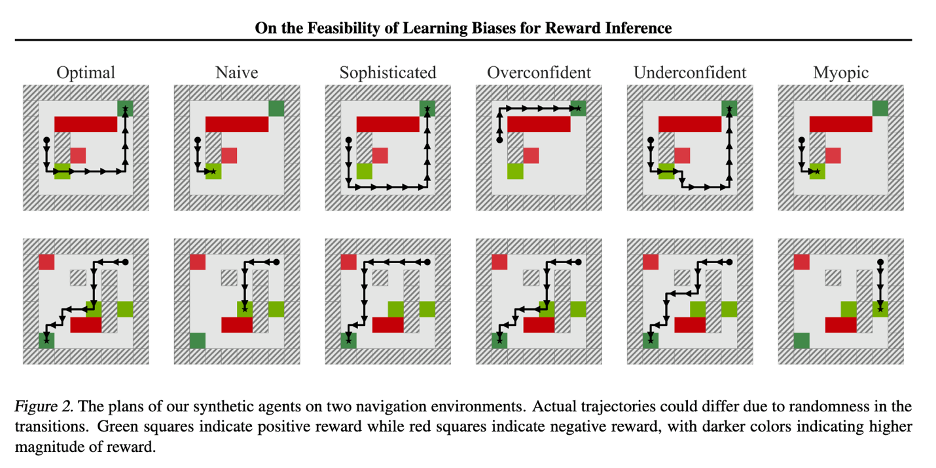
In addition to the naïve/sophisticated models described in the last paper, this paper adds several other examples of biases that humans can exhibit. Overconfident/underconfident agents incorrectly estimate probabilities, while myopic agents suffer from the horizon effect. All of these agents are simulated in a new MDP gridworld featuring rewards, punishments, walls, and uncertainty, as agents may randomly fail to execute the intended movement, and instead move orthogonally to the intended direction.
The architecture of the model is based on a differentiable planner called a value iteration network (VIN). There are two approaches to learning the agent’s biases and rewards – learning the planner from known rewards before the learning new rewards and learning both the planner and rewards simultaneously. A key step for this second approach is to initialize a near-optimal planner to start off with – this turns out to be crucial for good performance overall.
Shah et al. run several experiments on the different models and assumptions and find that these automatically learned biases tend to work just as well, or just slightly better, than standard IRL approaches. The issue is that the gains from learning the biases are offset by the downgrade from an exact approach to the differentiable NN approach. The authors claim that with better differentiable planners, this downside can be mitigated.
In terms of future work, the authors mention using more complicated problems with real people, and trying to approach the same problem with a reduced set of assumptions
The Moral Machine Experiment and Mathematical Notions vs. Human Perception of Fairness: A Descriptive Approach to Fairness for Machine Learning
These last two papers work in a completely different direction as the first three papers, and I’ll group them together since they are similar in idea.
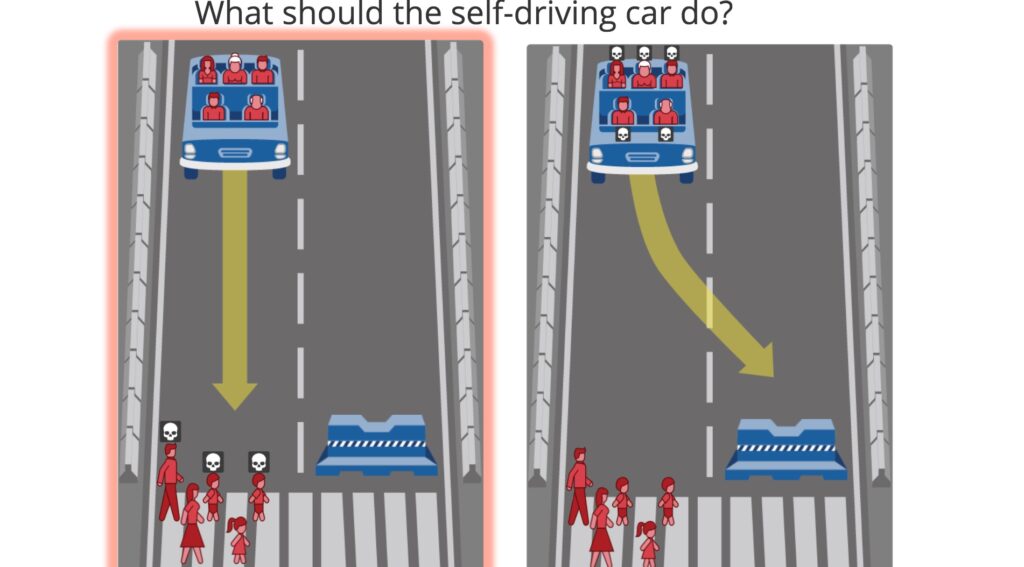
The Moral Machine paper conducts an experiment to understand human preferences on autonomous vehicle decisions and ethics. I didn’t really find there to be any particularly novel analysis in the paper, the notability from the paper comes from its massive sample size – millions of users from across the globe participated in the viral challenge. This allowed the authors to perform some cross-culture analysis based on locations of the users.
The second paper had a much smaller sample size but featured two different domains – criminal risk prediction and skin cancer risk prediction. The goals of the authors were to compare different models of fairness criteria, such as demographic parity, error parity, or equality of false discovery rates, instead of seeking to find tradeoffs between all of these at once, the approach in previous work. In order to understand the user’s preferences with a small number of trials, the authors used the EC2 algorithm, which dynamically chose new scenarios to prompt for based on the responses given in previous scenarios. Because this paper asked for demographic information, unlike the moral machine, the authors here were also able to analyze for cross-demographic variation (though they didn’t actually find any significant amounts).
Brainstorming Follow-up Research
After taking some time to think about these papers, I’ve started to come up with several follow-up questions and potential application domains. Of course, I’ll have to check with CJ first to see if my ideas are realistic or feasible, but I still have about 4 weeks left in the rotation, which is plenty of time to refine these ideas and develop a strong research question to start preliminary investigations on. Also, I haven’t really checked any of these ideas against the literature, so it’s possible that some of these have already been done.
- In the third paper, the authors describe a method to automatically learn biases in agents. However, it seems like these learned biases are lost in the blackbox of AI. Is it possible, given a large number of learned agents, to cluster the learned weights of the agent models, so that we can group together similarly biased agents together? We could also perhaps use this model agents with multidimensional biases (e.g. classifying an agent as 75% naïve and 66% myopic)
- Two games that we could use the domains to apply the techniques of biased IRL are Chess and Poker. Both of these domains would benefit as they are much more complex than the toy domains we’ve seen, but still have a closed and unambiguous set of states and actions to model. These also involve actual human behavior or biases that we can observe humans exhibit. I’m less familiar with poker, but chess has a very comprehensive database of games and positions to analyze, available freely and in an easy to use format. Both games have some sense of optimal decisions that we can compare against – Poker has probabilistic tables based on revealed information, and chess has engines like LC0 and SF12, which are so far ahead of humans, that we can essentially call them “perfect”, compared to human levels of play. Poker has degrees of uncertainty, which may be interesting to analyze.
- If we can compare deviations against optimality of systematically biased humans, can we do the same for systematically biased AI systems? It might be less interesting, though.
- Combining the two threads of IRL and fairness criteria, we could try to investigate learning fairness criteria by observing human behavior directly? I think this is an area that CJ was hinting at in our earlier call, but I’m not sure how exactly an experiment like this would be set up, in contrast to the two experiments we’ve already discussed.
- As I was reading through the fairness criteria papers, I remembered my meeting with the MVTA Executive Director, Luther Wynder. Luther explicitly brought up issues in fairness and equity when he was talking about why it would be very difficult for transit route planning to be automated, as well as considering other tradeoffs like ridership vs coverage, and political support. Maybe this is a difficult problem to really explore, since transit route planning is already very computationally expensive.
- The last two papers both had a few cross-demographic analyses on fairness criteria, and they both found very little significant results. However, I find this quite hard to believe, that everybody on earth views these topics the same, as this would make the fairness problem much easier to solve. It would be nice to do more experimentation of different demographics and see if there actually are systematic differences in how different groups of people view issues of algorithmic fairness.
This has been a really long blog post, but there’s been a lot to cover! All of this is very relevant to my ongoing rotation anyways, so writing this all down should be beneficial for the rotation. Even during the process of writing the blog, I’m understanding the papers better, so that’s already a benefit in itself.
Next week’s blog will probably be an update on how my research is going, see you then!


1 Comment
Rotation Paper Review 1 – Saumik Narayanan · October 31, 2020 at 6:12pm
[…] been given an assignment to do an in-depth paper review for each of our rotations. I already posted a general literature review summarizing a few papers related to my rotation research area, but this […]