Over the last few months, I've been working on a research project to develop personalized training tools for chess players. For this post, I'm just going to describe Maia, the framework developed last year which all of our code and models are based on.
Maia
Maia is a framework/model developed in 2020 by McIlroy-Young et al., which accurately predicts chess moves made by humans on Lichess. Essentially, their model took the neural network structure of Leela Chess (which I described in this post), and adapted it so that it predict what a human would play in a given position, instead of "the best" chess move in the position. Here's what the model looks like:
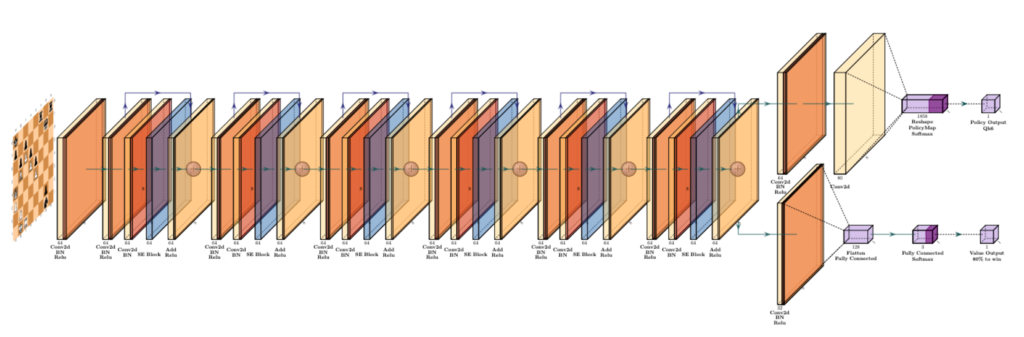
The architecture of this model is a Residual Convolutional Neural Network with 6 res blocks, and 64 filters per CNN layer. In plain English, a Convolutional Neural Network (CNN) is a type of neural network which uses filters instead of fully-connected layers, because of the the improved speed of computation and similar features of the data. Typically, CNNs are used in the field of computer vision, but as it turns out, they also work very well for chess boards! Instead of a typical 3-channel (RGB) image that you'd typically see, the chess board that Leela and Maia have uses 112 channels.
For a given chess board, there are 12 different types of pieces (White/Black) x (King/Queen/Bishop/Knight/Rook/Pawn), so each of these pieces takes up one channel in the input data. We also need a 13th channel, which keeps track of how many times this position has repeated (necessary for claiming threefold repetitions). In this way, we can represent a chess board in 13 channels.
Then, the input actually repeats this structure for the previous seven board states of the game, for the simple reason that it improves the model performance. (That's how a lot of ML is - arbitrary decisions that happen to work well 😄).
Finally, we have eight metadata channels, which represent things like castling rights, turns, and rule 50 counts.
In total, this gives us 13 + 13*7 + 8 = 112 channels! In general, understanding how channels work for CNNs is very important, so take some time so you understand how it works.
A Residual Neural Network (ResNet), is a more recent innovation in machine learning. Knowing how exactly it works isn't too important, but the main idea is that using these residual layers allows us to build very deep networks (hundreds or even thousands of layers), instead of the older models which could only train very few layers.
The main output of Maia is a 1858-vector, which represents the move prediction made by the model. The reason the output is 1858-length is because there happen to be exactly 1858 possible moves in chess (at least when represented using UCI Notation).
To predict these outputs, Maia was trained on millions of chess games played on Lichess.org. The biggest novelty of Maia's approach was that they actually segmented out the models, to predict moves played at different rating levels. Because of this, Maia could actually be thought of as a collection of models to predict moves at different levels. Maia-1 predicts moves played at the 1100-1199 range, Maia-2 predicts moves played at the 1200-1299 range, and so on.
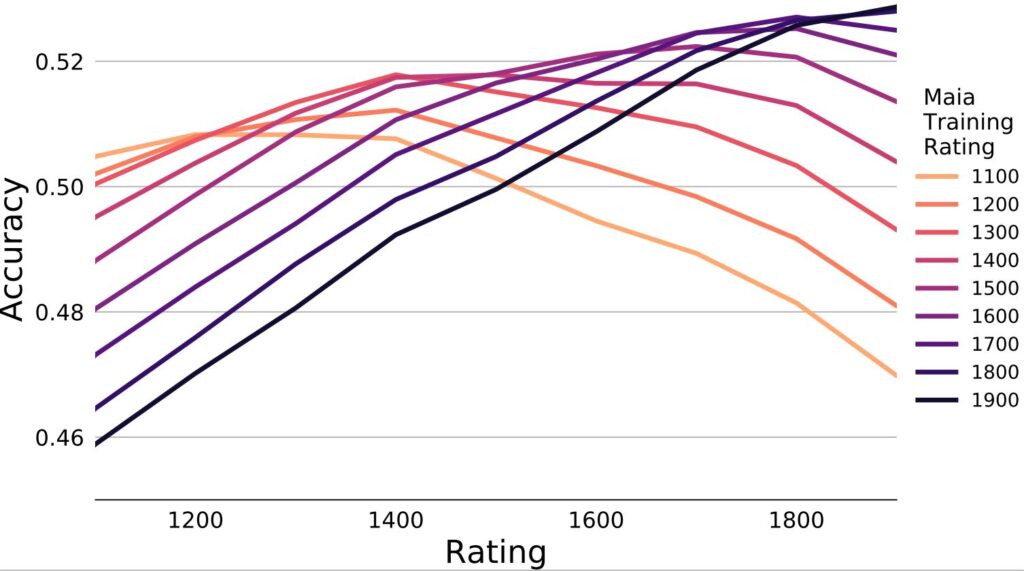
As you can see from this graph, the different levels of Maia performed better at their own rating than the other ratings. For example, Maia-4 was the best predictor of 1400-1499 players, and Maia-4 predicted these players better than it predicted 1300 or 1500 rated players.
Overall, Maia had incredibly impressive results. If you're interested in learning more about Maia, check out the source code, or a blog post published by Microsoft.


2 Comments
Tobi · January 20, 2024 at 9:16pm
Wondering, does it output like almost 100% for the move it considers most likely or does it also split the 100% regularly, like saying that one move has 60% and another 40%?
AMaiaNetworkUser · February 5, 2024 at 1:06am
Hi Tobi,
Did you get an answer to your question yet? I’d like to clarify how Maia’s neural network architecture works regarding its outputs and decision-making process, especially in the context of chess moves prediction.
Maia’s neural network has two primary outputs: policy output and value output. The policy output is essentially a distribution of all possible, legal moves available in a given position. It evaluates and ranks these moves based on their likelihood of being selected by a human player at the Elo rating Maia is trained for. This process involves analyzing the current position’s features, such as piece placement, control of the center, king safety, and more, to determine which moves are “promising.” By promising, we mean moves that are statistically likely for a player of a specific skill level to make, considering historical game data and positional analysis.
The value output, on the other hand, gives a probability (a percentage) of winning the game from the current position. Unlike the policy output, which focuses on move selection, the value output assesses the overall position’s favorability or likelihood of leading to a win, draw, or loss. This distinction is crucial because the most “human-like” move (policy output) might not always align with the move that maximizes winning chances (value output).
When Maia runs on a single node with no search enabled, it directly selects the top move from its policy output, meaning it prioritizes what a human at the targeted Elo would likely do over what would theoretically be the best move in a vacuum. Running on one node with no search essentially means Maia evaluates the position and decides on a move without deeper exploration of future possible moves (which would involve running multiple simulations or “searching” through a tree of move sequences). This approach ensures Maia’s moves are reflective of human play patterns at various skill levels, making it a valuable tool for training and analysis.
The allocation of node calculation time to promising lines is determined by how likely Maia assesses a move or sequence of moves to be chosen by a human player. This probabilistic assessment allows Maia to efficiently use its computational resources by focusing on analyzing moves that are more relevant to human play, enhancing its ability to predict and replicate human-like moves.
In summary, Maia’s architecture distinguishes between the policy output (selecting moves that a human would likely make) and the value output (evaluating the chances of winning from the current position). While these outputs serve different purposes, together they enable Maia to offer insights both into the strategic depth of chess and into the human-like decision-making process, balancing between mimicking human play and assessing winning probabilities.
Regarding your specific question about whether the policy output could be split between two moves, such as one move having a 60% likelihood and the other 40%, it’s important to understand that Maia evaluates and assigns probabilities to all possible, legal moves in a given position. While it’s theoretically possible for two moves to dominate the distribution in a highly specific or constrained scenario (for example, in positions with very few legal moves or where strategic considerations heavily favor a couple of options), Maia’s approach is to distribute probabilities across all legal moves based on their perceived likelihood of being selected by a human player.
In general, unless the position is extremely limited in terms of legal moves, the scenario you’ve described with one move having 60% and another 40% is unlikely.