Recently, I started a mini-project to write a Python script for transliterating the Tamil Script, since I couldn't find a good one which already existed. Transliteration (also known as Romanization) simply means taking the native Tamil Script, which looks something like தமிழ் அரிச்சுவடி, and turning it into something a phonetic representation using the Latin (English) script. Thus, தமிழ் அரிச்சுவடி could be transliterated as tamizh ariccuvaṭi.
Tamil Script Overview

The Tamil Script has a fairly regular Phonemic Orthography, where if you read a word, you know how to pronounce it, and if you hear a word, you usually know how to write it. (This is ignoring the whole Diglossia situation that Tamil has, and assumes that words are written using a colloquial spelling, or pronounced using the formal spelling)
Because of this, I figured that writing the code for transliteration would be easy. However, a few peculiarities of the Tamil writing script and Tamil Unicode representation made this harder than expected.
To start with, it's important to know that Tamil, like all Brahmi-derrived scripts are Abguidas, meaning that each syllable is written as a combination of a consonant and a vowel. In practice, this means that each combination syllable has a main consonant, and marker for which vowel should be sounded.
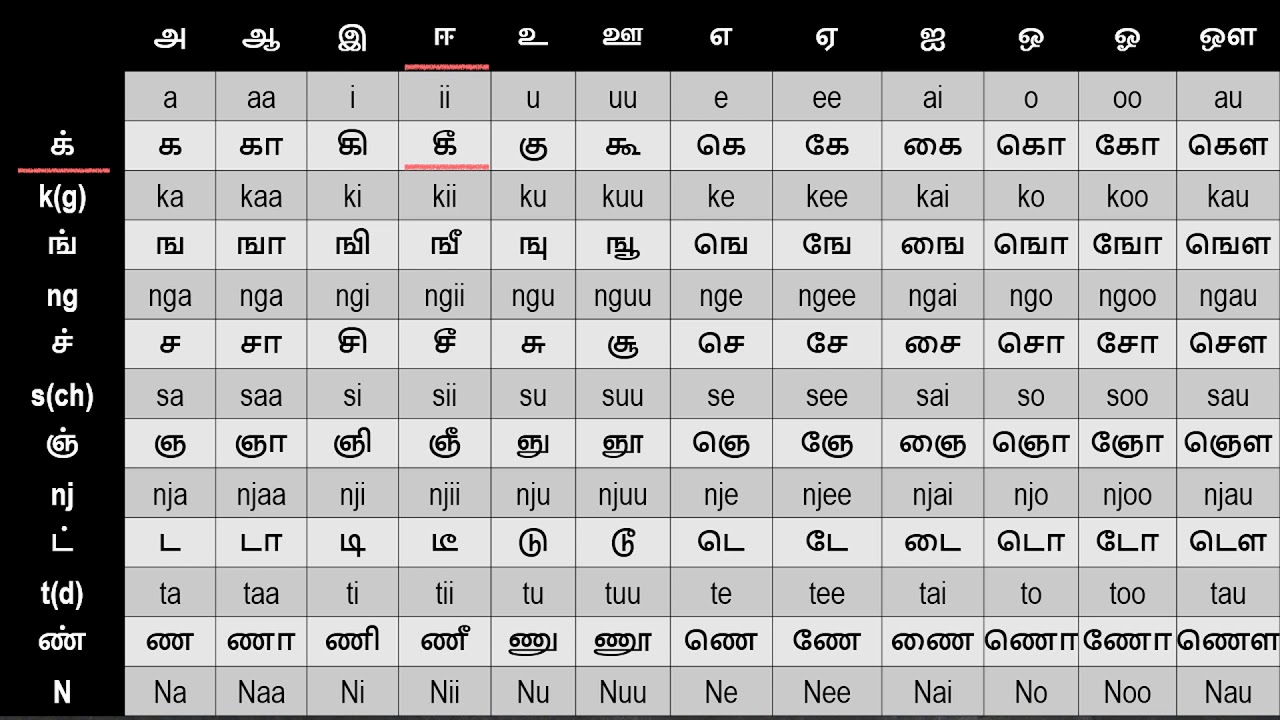
For example, if we want to write the syllable kii, we would take the letter க, pronounced ka, add the vowel marker for ii which is ீ, and when we combine these we get கீ. We can do the same thing for all the other vowel sounds as well to get all the syllables that start with k. Confusingly, if we don't add any vowel marker, we get the default a vowel, and if we want to have no vowel sound we need to add the anti-vowel marker ், so k would be க்.
If we want to write a vowel by itself, with no preceding consonant (which in Tamil usually only happens at the beginning of a word), there's a separate symbol that has to be learned (e.g.ii is ஈ)
For a full description of all of the consonants, vowels, and combinations, you can check out the Wikipedia page on the Tamil script.
How to Pronounce Tamil Sounds
Unfortunately, there isn't really a standard transliteration scheme which is used in practice1 for Tamil, and different texts tend to use different schemes for transliteration. It's sometimes so confusing that the same source might use multiple schemes in the same text! I want to create a more standardized scheme which makes sense for me and hopefully others, and one which is easy to implement in Python.
Vowels
For transliterating vowels, I chose to just follow the 7-bit ISO 15919 standard. 7-bit means that I use double letters to represent long vowel sounds (e.g. ஆ and is aa, not ā). The reason I chose this is that I think it's just slightly easier to read quickly, as it cuts down the number of diacritics that we have to pay attention to, and highlights the difference between short and long vowels better.
Quickly going over all the vowels, we have அ transcribed as a, which is pronounced as the English word "bus". அ is the only vowel with no corresponding vowel marker, since the lack of vowel marker inherently means a. ஆ and ா are both written as aa (as in the English word "far").
இ and ி are transcribed as i, and pronounced as the English word "bit". ஈ and ீ are transcribed as ii and pronounced as the English word "deep".
உ and ு are transcribed as u and pronounced as the English word "boot". ஊ and ூ are transcribed as uu, and pronounced like the previous letter but longer, something like "boooot".
எ and ெ are transcribed as e, and pronounced as the last sound in the French word "sauté", or like the English word "hey" if you get rid of the y sound at the end. ஏ and ே are transcribed as ee and are pronounced like எ but longer, so "sautéé". ஐ and ை are transcribed as ai, and pronounced like the English word "eye".
ஒ and ொ are transcribed as o, and pronounced like the first half of the English word "oh". ஓ and ோ are transcribed as oo, and pronounced like ஒ but longer, so "oooh". ஔ and ௌ are transcribed as au, and pronounced like the English word "cow"
Voiced/Unvoiced consonant pairs
Unlike virtually every other Brahmic language, Tamil doesn't distinguish between voiced and unvoiced consonants in their script. So, while Hindi writes ka as क and ga as ग, Tamil uses the same letter க for both ka and ga! While this might seem confusing, there's a simple set of rules for determining the pronunciation. When க comes at the beginning of a word, or when it's doubled (as in க்க) in the middle of a word, the sound is unvoiced (i.e. ka). When it's between two vowels, it's pronounced with voicing as as ga, and when க is preceded by a nasal sound (e.g. ங்க), it's also pronounced with voicing as nga. All nasal sounds in Tamil are voiced, just like English.
This entire behavior works because in native Tamil words, the sound g never appears at the beginning of a word. However, if a foreign word is loaned into Tamil which starts with g (e.g. governor), it will still be written as கவர்னர், and Tamil speakers would just know to pronounce it as a g instead of k.
In addition to க, this same voiced/unvoiced behavior happens with the letters ட, which can be either ṭa or ḍa, த, which can be either ta or da, and ப, which can be either pa or ba.
The letter ச almost follows this pattern as well. ச்ச in the middle of a word is c, and ச in the middle of a word is s. However, a word-initial ச can be pronounced as voiced or unvoiced (c or s) depending on the word and dialect! In my family's speech, it's usually a voiced s, though if you say it the other way, people will still understand you.
Transliterating Consonants
For each of the Tamil consonants, I now had to choose which Latin character to represent it as.
As mentioned, I transcribe க் as either k or g (pronounced as expected for an English speaker) depending on word location. If க்க் is doubled in a word, I'll write kk to follow convention, though I could have just as easily chosen k. ங் by itself is written as ng (i.e. the final sound in "singing" or the initial sound in "Nguyen"), and the nasal-consonant pair ங்க் is also written as ng, rather than ngg.
I transcribe ச் as c or s, depending on word location. c is really the ch-sound, as in church, but I write c for brevity, and because cc seems better than chch for ச்ச். ஞ் by itself is written as ñ (similar to the Spanish sound in "Español") and ஞ்ச் is written as nj (pronounced as in "ninja" or "injure").
I transcribe ட் as ṭ or ḍ2. These are retroflex sounds which are not actually found in English, though you can normally just pronounce them as of them as the regular t and d sounds, as in "toy" or "dine", and the sounds are close enough that everybody will understand you. ண் by itself is written as ṇ, and ண்ட் is ṇḍ.
I transcribe த் as t or d. These are really actually the "th" and "dh" sounds as in "think" or "they" (which probably should be written as "dhey"). ந் by itself is n and ந்த் is nd. Tamil also has the letter ன் which I also transcribe as n. This letter used to be pronounced differently from ந், with the tongue slightly farther back, but in modern Tamil dialects, the two sounds have merged 3 so I use the same transliteration for both.
I should note that the distinction between ṇ and n is very important in Tamil, though there is no such distinction in English. You can think of the difference between ṇ and n as the same as the difference as ṭ and t. If you alternate between the English words "tinker" and "thinker", you can feel the difference in tongue location, and you should try to emulate this difference when pronouncing ṇ and n.
Tamil also has the letters ள் and ல் , which I transcribe as ḷ and l. ள் is retroflex and has the tongue farther back in the mouth, while ல் has the tongue farther forward in your mouth, though they both make l-sounds.
I transcribe ப் as either p or b, pronounced the same way as in English. ம் by itself is m, and ம்ப் is mb (as in "number").
I transcribe ய் as y, pronounced the same way as in English. I transcribe வ் as v, pronounced the same way as in English.
I transcribe both ர் and ற் as r. In classical Tamil, these used to be pronounced differently, where ர் was tapped (as in the Spanish word "pero") and ற் was trilled (as in the Spanish word "perro"). However, in the modern day, most Tamil dialects have merged these two sounds together 3, so I simply use r for both.
Finally we have ழ், which is one of the sounds Tamil is most known for, compared to other Indian languages. This letter is usually transcribed as ḻ or, oddly enough zh, and I've chosen to use zh, just so it's more distinctive. This is actually the last sound in the word for the Tamil Language தமிழ்! So while the common English spelling for the word is in fact "Tamil", it would be transcribed as tamizh using this transliteration scheme, and this word tamizh is quite commonly used in Tamil Nadu.
To actually pronounce the letter ழ், you can just approximate it using the English letter R (as in "rabbit", "bar", or "arrow"). This isn't exactly correct, since it's technically a voiced retroflex approximant, but this is certainly good enough where you'll be understood.
This gives us all of the letters in the Tamil script. However, there are a few extra letters used for Tamil words borrowed from a different language (kinda like katakana in Japanese). Words containing these letters are usually relatively rare, and when you read them, you immediately know that it's a word foreign to Tamil (usually borrowed from either Sanskrit or English.)
These letters are ஜ, transcribed as j and pronounced as the English word "jam", ஶ and ஸ, which are both transcribed as s, like the English word "sip", ஷ, transcribed as sh and pronounced like the English word "ship", and ஹ, transcribed as h and pronounced like the English word "hip".
Using this scheme, you now know how to pronounce and transliterate ever letter and sound in Tamil. As an example, the English word for Tamil is written in the Tamil script as தமிழ், is transcribed as tamizh, and would be pronounced along the lines of "thuh-mur" for an English speaker! This is admittedly a bit confusing, but it's consistent, and you'll quickly get the hang of it as you read more, and perhaps listen to some audio as you go along.
Transliterating Tamil using Python
Using this scheme from above, I wanted to write a Python function to take any given Tamil script text, and transliterate it into this scheme. In order to do this, there were two main issues I faced.
First, I had to deal with the voiced/unvoiced consonant pairs, where the same letter க் should be written as k in some places and g in other places. Second, I had to deal with the internal Unicode representation of Tamil consonant-vowel combinations, where the lack of a vowel marker signifies the letter a, and a special vowel marker ் removes the vowel sound.
To solve the second issue, I decided to run the transcription at the syllable level, rather than the individual character level. For example, the Tamil syllable கோ for koo is actually written as க+ோ. If we replaced க and ோ separately, we would end up with kaoo, but we avoid this issue by replacing it at the syllable level. The only thing we need to watch out for is that we have to replace க after all the other vowel combinations (e.g. கா, கி), and individual sound க் which doesn't contain a vowel.
To solve the first issue, I handle these special consonant separately, using a bit of Python regex. Essentially, I first find all the doubled consonants, and treat them as a single syllable (e.g. I would replace க்கோ with kkoo, rather than k and koo).
I then find instances where க is at the start of a word, essentially replacing the regex string r'(^|\s)க' with r'\1k'. If you don't know what this means in Python, an r-string (e.g. r'something') means you ignore backslashes which is important for regex expressions. (^|\s) means I match either a new string ^ or a space \s immediately followed by க, and I replace it with the first character found (either new string or space) plus க.
I then handle nasal+consonant combinations, such as ங்க before going through the rest of the consonants. If I handle the replacements in this order, any extra க் we find by this point is guaranteed to be g, not k, which simplifies our work.
Because I have to do this for every consonant and every vowel, I can just find each of these combinations in a double for-loop. Finally, I handle all the syllables which are just a vowel, without any consonant.
consonants = {'க்க':'kk','ச்ச':'cc','ட்ட':'ṭṭ','த்த':'tt','ப்ப':'pp',
'ங்க':'ng','ஞ்ச':'nj','ண்ட':'ṇḍ','ந்த':'nd','ம்ப':'mb',
r'(^|\s)க':r'\1k',r'(^|\s)ச':r'\1c',r'(^|\s)ட':r'\1ṭ',
r'(^|\s)த':r'\1t',r'(^|\s)ப':r'\1p',
'க':'g','ங':'ng','ச':'s','ஞ':'ñ','ட':'ḍ','ண':'ṇ',
'த':'d','ந':'n','ப':'b','ம':'m','ய':'y','ர':'r',
'ல':'l','வ':'v','ழ':'zh','ள':'ḷ','ற':'r','ன':'n',
'ஜ':'j','ஶ':'s','ஷ':'sh', 'ஸ':'s','ஹ':'h'}
vowels1 = {'ா':'aa','ி':'i','ீ':'ii','ு':'u','ூ':'uu','ெ':'e','ே':'ee',
'ை':'ai','ொ':'o','ோ':'oo','ௌ':'au','்':'','':'a',}
vowels2 = {'அ':'a','ஆ':'aa','இ':'i','ஈ':'ii','உ':'u','ஊ':'uu',
'எ':'e','ஏ':'ee','ஐ':'ai','ஒ':'o','ஓ':'oo','ஔ':'au',}
def transliterate(str):
for c1, c2 in consonants.items():
for v1, v2 in vowels1.items():
str = re.sub(c1+v1, c2+v2, str)
for v1, v2 in vowels2.items():
str = re.sub(v1, v2, str)
return str
While this code isn't very long, it took a bit of thinking to get both of these cases working, and I'm quite happy with the end result, it's pretty elegant in my opinion. I've also uploaded the code as a Github Gist, for easy reference.
Conclusion
Hopefully after reading this post, you know how the Tamil script works, how to pronounce each of the letter and syllables, and how to use Python to transliterate your own texts for easier pronunciation. With a bit of practice, you'll be able to read and pronounce any Tamil word or text, though you probably won't understand any of it :).
-
By scheme, I mean the choice of which Latin characters and diacritics are used to represent the consonants and vowels in Tamil ↩
-
Some other sources use ʈ and ɖ, and I've used these symbols in the past, but I think the dots in ṭ and ḍ just look slightly nicer and more distinguishable from the unmarked letters, especially when you consider the other two retroflex characters for ɳ/ɭ vs ṇ/ḷ. This choice also follows the standard set in ISO 15919 ↩
-
https://www.cambridge.org/core/journals/journal-of-the-international-phonetic-association/article/tamil/5BE3F9D1C8291CDA6B3610F0E1079C02 ↩ ↩


0 Comments