Introduction
After I graduated from college in May, I didn’t want to immediately start searching for jobs for two main reasons. The first was simply that I wanted to take a break, and do things that I wanted to focus on, at my own pace, instead of worrying about deadlines for tasks imposed on me by others. The second was that I didn’t think I was ready to immediately start interviewing with companies for data science or machine learning positions.
During college, I took a number of relevant technical classes which were great for building my theoretical understanding of many important concepts. However, one of limitations of these courses was that they didn’t spend enough time teaching the applied methods needed to use these concepts on my on projects, or in the workplace.
For example, in my Computer Vision course, we learned how to implement a convolutional neural network in MATLAB and apply it to the MNIST dataset. But in my job, nobody is going to ask me to implement my own CNN; they’ll ask me to use one of the many implementations already available and tune it to perform on their own dataset. Not only did I not know how to tune the hyperparameters of a neural network for a real-world dataset, I didn’t even have any experience using any common machine learning frameworks like Tensorflow or PyTorch.
Before starting to apply for jobs, I knew that I needed to spend time learning more of the tools which I would actually need during my job, as well as practicing using them. I decided to devote at least a month towards self-study before starting my job hunt. My goal was to mainly focus on topics in data science and machine learning, but also touch on some other topics like web dev, databases, and general math/stats skills.
Kaggle Learn
According to Wikipedia, “Kaggle is an online community of data scientists and machine learners, … [which] allows users to find and publish data sets, explore and build models in a web-based data-science environment, work with other data scientists and machine learning engineers, and enter competitions to solve data science challenges.” I had been introduced to Kaggle several years ago, and I had made an account, but I never got around to actually doing anything in Kaggle until recently.
After graduating, I was looking for online resources for studying data science, and I stumbled upon Kaggle Learn. Kaggle Learn is a platform where experienced data scientists teach practical data skills, and allow you to immediately use these skills in Kaggle’s version of Jupyter Notebooks, called Kaggle Kernels.
The list of courses offered on Kaggle is constantly evolving, with a new course coming every few months. Currently, the offered courses are:
- Python
- Intro to Machine Learning
- Data Visualization: from Non-Coder to Coder
- Intermediate Machine Learning
- Pandas
- Deep Learning
- Data Visualization
- Intro to SQL
- Microchallenges
- Embeddings
- Machine Learning Explainability
Of these courses, I skipped Python, the first Data Visualization course, and Pandas because I was already confident enough in my abilities with these skills. I also skipped Intro to SQL because I was planning on taking Mode’s SQL course instead.
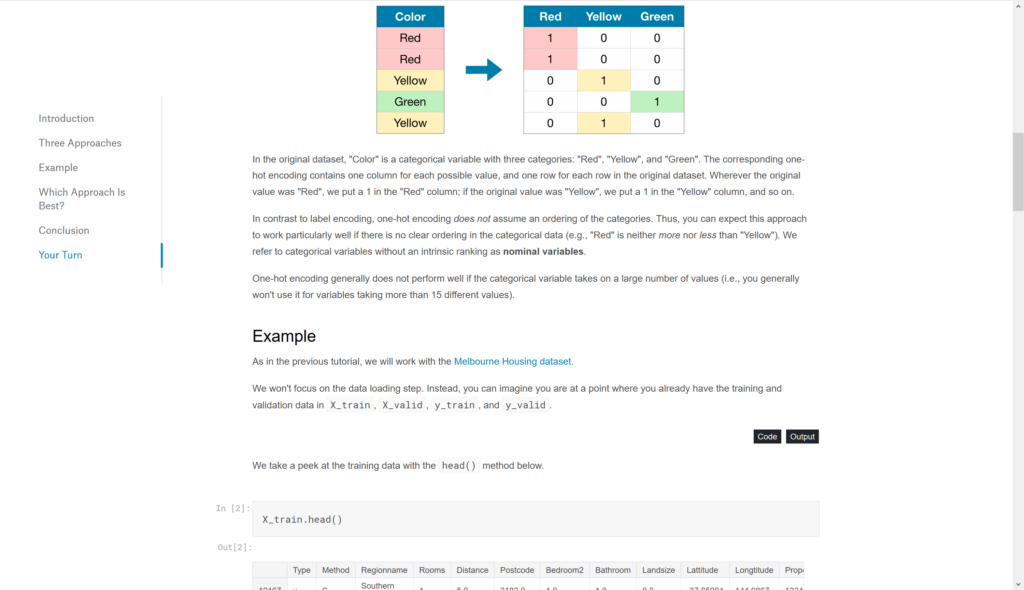
Review of Kaggle Learn
What I liked most about these courses is the minimalism. All readers are shown is a summary of a topic, relevant code snippets + output, and a brief explanation. Then, the reader gets to practice along by immediately implementing the code in their own Kaggle Kernel. I don’t think this format is great for actually internalizing what is going on behind the scenes, but I think it does an effective job at presenting the core ideas, so that when students are doing this later, they already have a basic understanding to start from.
For example, in the Intro to Machine Learning course, the content is on decision trees, random forests, and model performance. The course doesn’t cover any other ML models, and if you take this course quickly, you probably aren’t going to understand whats going on behind decision trees or random forests either. However, you will get an understanding on what machine learning models are, and that they have some sort of performance metric, even if you forget what it actually is. Then, when you are learning more complicated things, you can use this base knowledge to guide yourself.
I think most of the content is like this as well. By itself, you won’t really get a firm grasp of concepts like Data Leakage, or Convolutions, or Embeddings. But when you are actually doing real work and you encounter one of these topics, you can say “Hey, I remember Embeddings”, and pick it up more quickly instead of getting lost in a sea of machine learning concepts.
While most of these courses are structured in this very simple manner, I think that the one topic they fail is the Deep Learning micro-course. Instead of teaching simple overviews of concept, they go a little deeper and present short videos (3-10 minutes) on each concept like Convolutions, Transfer Learning, and Gradient Descent. I already had a good knowledge of all these coming into the course, so I didn’t really learn much from this micro-course anyway. However, I also don’t think that the Kaggle Learn platform is suited for these more complicated topics, and your time would be better spent on a different website instead.
Instead of trying to explain these more complicated concepts, it would be better to keep covering simple topics that can be explained with just short text and code examples. Maybe you can still explain the topics a little, and show how to implement them in Python, but the videos are too much, I think. Of course, I don’t think going deeper into the content can hurt, but it goes against the core idea of platform which is to immediately get going with the content.
Finally, I especially liked the Micro-challenges section. While it isn’t actually a course, it’s a very simple way of transitioning from learning the topics to starting in Kaggle Competitions. After all, Kaggle is a business and they want to promote their own products, but I like it anyway, because it shows students how to keep using their skills on more “real” problems in the actual micro-courses. In fact, I would have liked to have even more of these micro-challenges, since I think they’re a great way to learn.
Conclusion
If you’re looking to go deeper in your understanding with machine learning, and learn a range of applications as well as what’s happening under the scenes, Kaggle Learn is probably not right for you, since it only covers a few important ideas without too much explanation. However, if you just want to get your feet wet with machine learning and data science, without putting in too much effort, or you’re focused on implantation instead of understanding, I would definitely recommend trying out Kaggle Learn.
If you’re looking for more involved online courses, I’ll cover a few more that I took this summer in my upcoming blog posts! I’ll be talking about Mode’s SQL course, FastAI’s Practical Deep Learning course, CommonLounge’s Hadoop course, and Deeplearning.ai’s Deep Learning specialization. Make sure to check back in the next week or so to see my next post.
See you soon!
Saumik


4 Comments
Anxious Reader · August 26, 2019 at 12:26pm
“Make sure to check back in the next week or so to see my next post.”
It has been over a month. Wheres the next post???
Saumik · September 27, 2020 at 7:53pm
I’ve made a new commitment to post blogs every week :).
Hopefully I can follow through this time…
https://saumikn.com/blog/starting-weekly-blog/
Yusuf B. · July 2, 2020 at 11:51am
Hi Saumik,
I took the first three courses of Applied Data Science with Python Specialization from University of Michigan on Coursera recently. I wanted to ask your opinion of Kaggle Competitions. Would it be a good place to start practicing what I learned or do you know other platforms that could help with building a portfolio of projects?
Thanks…
Saumik · September 27, 2020 at 7:54pm
I’ve never done Kaggle Competitions myself, or heard much about them, but it’s probably a good way to practice.